 Overlapping Communication and Computation Overlapping Communication and Computation
Overlapping Communication and Computation Overlapping Communication and ComputationAsynchronous communication primitives also allow one to overlap the costs of communication and computation. Consider the following code fragments:
A () { B () {
repeat { repeat {
read for this iteration; read for next iteration;
compute for this iteration; compute for this iteration;
} }
} }
The communication in function A must be synchronous while it can be asynchronous in function B to allow the overlap of communication and computation. Although the behavior and performance of these two programs are likely to be quite different, the traffic per instruction metric, unfortunately, again fails to provide any insight. We wrote a few toy kernels that have the same amount of communication per instruction but employ different types of memory operations. We run these kernels on the CM5 and the T3D, and we noticed, not surprisingly, drastic improvements in the running time for the kernels with asynchronous memory operations. The following graph shows one of the sample results.
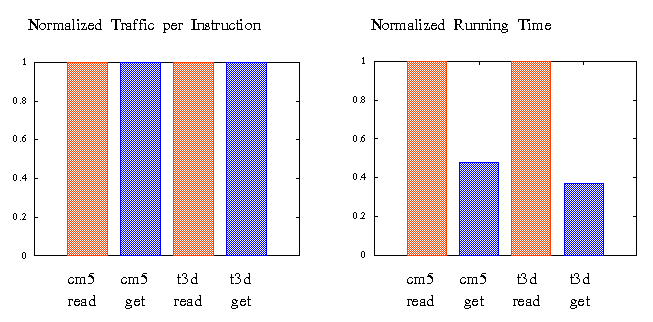
Such differences in communication behavior can have important implications for an architect. For example, program IO will probably do just fine for function A but function B can potentially benefit significantly from DMA. Furthermore, depending on how sophisticated the ``read'' is, one might even want a second network processor to handle the traffic. Then there is the question of how powerful this processor needs to be. Needless to say, a traffic per instruction number hardly sheds any light for such questions.
To better model such communication characteristics, in addition to a message size distribution, we propose yet another histogram that shows how much computation can be performed before we demand the result of the previously initiated communication.