We now consider throughput improvements and address the following questions: 1) How do we schedule the requests to take advantage of the additional resources? 2) How do we modify the SR-Array aspect ratio models to optimize for throughput?
Scheduling on an SR-Array
In our SR-Array design, we choose to place a block and all its replicas (if any) on a single disk. Requests are sent to the only disk responsible for the data, which queues requests and performs scheduling on each disk locally and independently. In contrast, in a mirrored system, because any request can be scheduled for any copy, devising a good global scheduler is non-trivial. We report heuristics-based results for mirrored systems in later sections. In this section, we focus on scheduling for an SR-Array and develop an extension of the LOOK algorithm for an SR-Array, which we call RLOOK.
Under the traditional LOOK algorithm, the disk head moves bi-directionally from one end of the disk to another, servicing requests that can be satisfied by the cylinder under the head. On an SR-Array disk, in addition to scanning the disk like LOOK in the seek direction, our RLOOK scheduling also chooses the replica that is rotationally closest among all the replicas during the scan.
Suppose q is the number of requests to be scheduled for a single
RLOOK stroke on a single disk, and S, R, Ds, Dr, D, and p retain
their former definitions from
Section 2.3, the average time
of a single request in the stroke is
T(Ds, Dr):
Starting with Equation (12),
we can prove that
the best latency is achieved with the following configuration:
In addition to the parameters that we have seen in the previous
models, the aspect ratio is now also sensitive to q, a measure of
the busyness of the system. A long queue allows for the amortization of the
end-to-end seek over many requests; consequently, we should devote
more disks to reducing rotational delay. In terms of the SR-Array
illustration of Figure 3(b), this argues for a tall thin
grid. As with the model in the last section, a p ratio under 50% also
precludes rotational replication; pure striping is best and Equations (13) through
(15) do not apply.
In the best case, when all replicas are propagated in the background,
p approaches 1, and the model suggests that the overhead-independent part
of service time also improves proportionally to ![]() .
.
Having modeled the throughput of a single disk, we attempt to model
the throughput of an SR-Array with D disks and a total of Q=D qoutstanding requests, where q is the average queue size per disk.
We assume that the
requests are randomly distributed in the system. There could be a
load imbalance in the form of idle disks when Q is not
much more than D. The probability of one disk being idle is
![]() .
Therefore, the total throughput of the
system is:
.
Therefore, the total throughput of the
system is:
Although this approximation is derived based on reasoning about the presence of idle disks, we shall see in Section 4.2 that it is in fact a good approximation of more general cases.
Now that we have described the RLOOK extension to LOOK, it is easy to understand a similar extension to SATF: RSATF. An RSATF scheduler chooses the next request with the shortest access time by considering all rotational replicas. It is well known that SATF outperforms LOOK [14,23] by considering rotational delay. Our experimental results will show that the gap between RLOOK and RSATF is smaller because both scheduling algorithms consider rotational delays. Once the detailed low level disk layout is understood, RLOOK is simple to implement; it is an attractive local scheduler for an SR-Array.
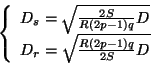
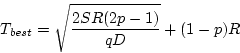
![\begin{displaymath}
N_{D} \approx D\left[ 1-\left( 1-\frac{1}{D}\right) ^{Q}\right] \cdot N_{1}
\end{displaymath}](img26.gif)