


Next: Validating the Integrated Simulator
Up: Logical-to-physical Address Mapping
Previous: Querying the Mapping
Updating and Recovering the Mapping with Incremental Checkpointing
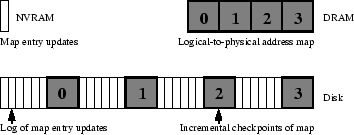
Figure 7:
Logging of logical-to-physical map updates
and incremental checkpointing of the map.
 |
In designing a mechanism to keep the logical-to-physical address map
persistent, we strive to accomplish two goals: one is low overhead
imposed by the mechanism on ``normal'' I/O operations, and the other
is fast recovery of the map.
Figure 7 shows the map-related data structures used
in various storage levels. Updates to the logical-to-physical map are
accumulated in a small amount of NVRAM. When the NVRAM is filled, its
content is appended to a map log region on disk. (Both the
NVRAM and the map log region on disk can be replicated for increased
reliability.) We divide the logical-to-physical address map into 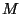 portions. (
portions. (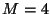 in Figure 7.) Periodically, a portion
of the map is checkpointed as it is appended to the log. After all
portions of the map are checkpointed, the map update log
entries that are older than the th oldest checkpoint can be freed
and this freed space can be used to log the new updates. The size of
the map log region on disk is bound by the frequency and the size of
the checkpoints. When we reach the end of the log region, the log can
simply ``wrap around'' since we have the knowledge that the log
entries at the beginning of the region must have been freed. The
location of the youngest valid checkpoint is also stored in NVRAM.
During recovery, we first read the entire map log region on disk to
reconstruct the in-memory logical-to-physical address map, starting
with the youngest valid checkpoint. We then replay the log entries
buffered in NVRAM. At the end of this process, the in-memory
logical-to-physical address map is fully restored.
We note a number of desirable properties of the mechanism described
above. The size and frequency of the checkpoint allows one to trade
off the overhead during normal operation against the map recovery
time. In particular, the checkpoints bound the size of the map log
region, thus bounding the recovery time. Incremental checkpointing
prevents undesirable prolonged delays associated with the
checkpointing of the entire map. It also allows the space occupied by
obsolete map update entries to be reclaimed without expensive garbage
collection of the log.
It is interesting to compare the mechanism employed in managing the
logical-to-physical address map of an EW-Array against those employed
in managing data itself in a number of related systems such as an
NVRAM-backed LFS [1,21] and
RAPID-Cache [13]. While we buffer and checkpoint
metadata, these other systems buffer and reorganize data.
The three orders of magnitude difference in the number of bytes
involved makes it easy to control the overhead of managing metadata in
an EW-Array.
Practically, in a
in Figure 7.) Periodically, a portion
of the map is checkpointed as it is appended to the log. After all
portions of the map are checkpointed, the map update log
entries that are older than the th oldest checkpoint can be freed
and this freed space can be used to log the new updates. The size of
the map log region on disk is bound by the frequency and the size of
the checkpoints. When we reach the end of the log region, the log can
simply ``wrap around'' since we have the knowledge that the log
entries at the beginning of the region must have been freed. The
location of the youngest valid checkpoint is also stored in NVRAM.
During recovery, we first read the entire map log region on disk to
reconstruct the in-memory logical-to-physical address map, starting
with the youngest valid checkpoint. We then replay the log entries
buffered in NVRAM. At the end of this process, the in-memory
logical-to-physical address map is fully restored.
We note a number of desirable properties of the mechanism described
above. The size and frequency of the checkpoint allows one to trade
off the overhead during normal operation against the map recovery
time. In particular, the checkpoints bound the size of the map log
region, thus bounding the recovery time. Incremental checkpointing
prevents undesirable prolonged delays associated with the
checkpointing of the entire map. It also allows the space occupied by
obsolete map update entries to be reclaimed without expensive garbage
collection of the log.
It is interesting to compare the mechanism employed in managing the
logical-to-physical address map of an EW-Array against those employed
in managing data itself in a number of related systems such as an
NVRAM-backed LFS [1,21] and
RAPID-Cache [13]. While we buffer and checkpoint
metadata, these other systems buffer and reorganize data.
The three orders of magnitude difference in the number of bytes
involved makes it easy to control the overhead of managing metadata in
an EW-Array.
Practically, in a
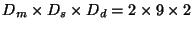 EW-Array prototype (whose disks are 9 GB
each), with a 100KB NVRAM to buffer map entry updates, we have
observed that
the amount of overhead due to the maintenance of the map
during normal operations of the TPC-C workload is below 1%
and it takes 9.7 seconds to recover the map.
The recovery performance can be further
improved if we distribute the map log region across a number of disks
so the map can be read in parallel.
EW-Array prototype (whose disks are 9 GB
each), with a 100KB NVRAM to buffer map entry updates, we have
observed that
the amount of overhead due to the maintenance of the map
during normal operations of the TPC-C workload is below 1%
and it takes 9.7 seconds to recover the map.
The recovery performance can be further
improved if we distribute the map log region across a number of disks
so the map can be read in parallel.
Next: Validating the Integrated Simulator
Up: Logical-to-physical Address Mapping
Previous: Querying the Mapping
Chi Zhang
2001-11-16